An article in the New Scientist – here – discusses this paper on arxiv on the non-random distribution of the prime numbers.
So what? After all, we know that primes are not randomly distributed and become increasingly less common as we progress up the “number line” – with the Prime Number Theorem telling us that the number of primes up to or less than 
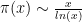
(This is also takes us to perhaps the best known paradoxes of infinity – even though we know that primes become increasingly rare as we count higher, we also know there are an infinite number of primes: if we had a maximum prime 
But the lack of randomness here is something deeper – there is a connection between successive primes, something rather more unexpected.
For any prime greater than 5 counted in base 10 we know it must end in either 1, 3, 7 or 9. The even endings (0, 2, 4, 6, 8) are all divisible by 2, while those that end in 5 are also divisible by it (this is what made learning the five times tables so easy for me in Mrs McManus’s P3 class forty-three years ago – the girls on the street loved a skipping rhyme and all I had to do was sing it in my head: five, ten, fifteen, twenty…).
The thinking was that these endings would be randomly distributed, but they are not (a simple result to demonstrate, so it is a sign that not all interesting maths research is yet beyond us mere mortals.)
To simplify things a bit, though, I am (as does the arxiv paper) going to look at the residues the primes leave in modulo 3 counting. Essentially this just means the remainder we get when divide the prime by three (there has to be a remainder, of course, because otherwise the number would not be prime). As is obvious these have to be 1s or 2s – e.g., 5 has a residue of 2, 7 a residue of 1 and so on.
What we are really interested in is the sequence of these residues. If successive primes were wholly independent then we would expect these sequences – i.e., (1, 1) or (1, 2) or (2, 1) or (2, 2) to all be equally likely. Using mathematical notation we describe the frequency of these sequences like this: 
For the first million primes we would expect each sequence to have 250,000 occurrences or something very close to that. But we don’t see that at all:
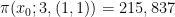
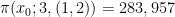

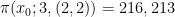
Using a list of primes I found online and some C++ and R (listed at the end if you want to mess about with it yourself), I decided to using a little bit of Bayesian inference to see how the non-random the primes are.
I treated the sequences as though they were coin tosses – if we get a switch (1, 2) or (2, 1) then that is the equivalent of a head, while if we get a recurrence (1, 1) or (2, 2) then we have had the equivalent of flipping a tail. If the coin was “fair” then for a 1000 flips we’d get 500 of each type. The result for the first 1000000 primes, though, suggests we’d actually get 568 heads.
(I discussed Bayesian testing for coin fairness some time ago – here.)
With Bayesian inference we can posit a “prior” – a guess, educated or otherwise – as to how fair the coin we are testing might be. If we know nothing we might start with a prior that assigned equal likelihoods to all results, or we might, in this case, go for a (in retrospect naive) view that the most likely outcome is fairness and that subsequent primes are independent of those that went before.
The first graph – below – is based on saying we are ignorant of the likely result and so assigns an equal likelihood to each result. (A probability of 1 indicates absolute certainty that this is the only possible outcome, while a probability of 0 indicates there is literally zero chance of this happening – it should be noted that using Bayesian inference means we are looking at a prediction for all primes, not simply the results of the first 1000 we test.)

This looks at the first thousand primes and predicts we’d get something like 650 – 660 heads (if you look closely you’ll see that even as the probability density graph becomes narrower it also moves slowly to the left.)
The second graph does the same but posits a different prior – one where the initial guess is that, quite strongly, the “coin” is a fair one. That makes a big difference for the first few primes but it does not take long before the two graphs look exactly the same.

So does this lack of randomness indicate a shocking and previously undetected “hidden hand” in number theory? It seems not (I don’t claim to follow the maths of the paper at this point): the authors explain can explain the pattern using what we already know about primes and also point out that, as we further extend our examination we find the result is increasingly “fair” – in other words, the probability density spike would creep ever closer to 500 in the graphs above. (This also shows that even quite large sample sizes are relatively poor guides to the final result if the sampling is not truly random, but that is another matter entirely).
This is a reworked and consolidated post from what were the two previous posts on this subject.
Here’s the code
#include <iostream>
#include <fstream>
#include <string>
#include <sstream>
#include <vector>
#include <cmath>
using namespace std;
void normalise(vector<long double>& input)
{
long double sum = 0;
for (auto x: input) {
sum += abs(x/sizeof(input));
}
long double factor = 1/sum;
for (auto& x: input) {
x = x * factor;
}
auto biggest = max_element(input.begin(), input.end());
if (*biggest > 1) {
factor = 1/(*biggest);
for (auto& x: input) {
x = x * factor;
}
}
}
int main()
{
vector<int> primes;
//read in the primes file
ifstream inputPrimes("/Users/adrian/Downloads/P-1000000.txt");
//get the primes
string rawPrimeLine;
while (getline(inputPrimes, rawPrimeLine)) {
string ordinal;
string prime;
istringstream stringy(rawPrimeLine);
getline(stringy, ordinal, ',');
getline(stringy, prime, ',');
primes.push_back(atol(prime.c_str()));
}
//calculate bayes inference
ofstream bayesOut("/Users/adrian/bayesout.csv");
vector<long double> distribution;
for (int i = 0; i <= 1000; i++) {
distribution.push_back(0.0001 + pow(500 - abs(i - 500), 4));
// distribution.push_back(0.001);
}
normalise(distribution);
int last = 1; //7%3 = 1
int count = 2;
int heads = 1;
//heads = switch
//tails = no switch
//0 = all tails, 1 = all heads
for (auto p: primes) {
if (p > 7 && count < 1010) {
count++;
int residue = p%3;
long double hVal = 0.0;
if (residue != last) {
heads++;
}
for (auto& x: distribution) {
x *= pow(hVal, heads) * pow(1 - hVal, count - heads);
hVal += 0.001;
}
normalise(distribution);
last = residue;
int numb = 0;
for (auto x: distribution) {
if (numb++ > 0) {
bayesOut << ",";
}
bayesOut << x;
}
bayesOut << endl;
}
}
}
#!/usr/bin/env Rscript
library("animation")
w2<-read.csv("/Users/adrian/bayesout.csv")
saveGIF({
optos = ani.options(nmax=1000)
for (i in 1:ani.options("nmax")) {
matplot(t(w2)[,i], ylim=c(0, 1), axes=FALSE, ylab="Probability", xlab=c("Outcome: ", i), type="l")
axis(side = 1, at = c(0, 100, 200, 300, 400, 500, 600, 700, 800, 900, 1000))
axis(side = 2, at = c(0, 1))
ani.pause()
}}, interval=0.15, movie.name="primes.gif", ani.width=400, ani.height=400)








2 responses to “Primes are not random”
[…] Read more here:https://cartesianproduct.wordpress.com/2016/03/24/primes-are-not-random/ […]
[…] Primes are not random […]