
Inspired by an article in the New Scientist I am returning to a favourite subject – whether P = NP and what the implications would be in the (unlikely) case that this were so.
Here’s a crude but quick explanation of P and NP: P problems are those that can be solve in a known time based on a polynomial (hence P) of the problem’s complexity – ie., we know in advance how to solve the problem. NP (N standing for non-deterministic) problems are those for which we can quickly (ie in P) verify that a solution is correct but for which we don’t have an algorithmic solution to hand – in other words we have to try all the possible algorithmic solutions in the hope of hitting the right one. Reversing one-way functions (used to encrypt internet commerce) is an NP problem – hence, it is thought/hoped that internet commerce is secure. On the other hand drawing up a school timetable is also an NP problem so solving that would be a bonus. There are a set of problems, known as NP-complete, which if any one was shown to be, in reality a P problem would mean that P = NP – in other words there would be no NP problems as such (we are ignoring NP-hard problems).
If it was shown we lived in a world where P=NP then we would inhabit ‘algorithmica’ – a land where computers could solve complex problems with, it is said, relative ease.
But what if, actually, we have polynomial solutions to P class problems but there were too complex to be of much use? The New Scientist article – which examines the theoretical problems faced by users of the ‘simplex algorithm’ points to just such a case.
The simplex algorithm aims to optimise a multiple variable problem using linear programming – as in an example they suggest, how do you get bananas from 5 distribution centres with varying numbers of supplies to 200 shops with varying levels of demand – a 1000 dimensional problem.
The simplex algorithm involves seeking the optimal vertex in the geometrical representation of this problem. This was thought to be rendered as a problem in P via the ‘Hirsch conjecture‘ – that the maximum number of edges we must traverse to get between any two corners on a polyhedron is never greater than the number of faces of the polyhedron minus the number of dimensions in the problem.
While this is true in the three dimensional world a paper presented in 2010 and published last month in the Annals of Mathematics – A counterexample to the Hirsch Conjecture by Francisco Santos has knocked down its universal applicability. Santos found a 43 dimensional shape with 86 faces. If the Hirsch conjecture was valid then the maximum distance between two corners would be 43 steps, but he found a pair at least 44 steps apart.
That leaves another limit – devised by Gil Kalai of the Hebrew University of Jerusalem and Daniel Kleitman of MIT, but this, says the New Scientist is “too big, in fact, to guarantee a reasonable running time for the simplex method“. Their two page paper can be read here. They suggest the diameter (maximal number of steps) is 
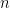
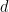
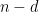
So for Santos’s shape we would have a maximal diameter of 

I think these figures suggest that proving P = NP might not be enough even if it were possible. We might have algorithms in P, but the time required would be such that quicker, if somewhat less accurate, approximations (as often used today) would still be preferred.
Caveat: Some/much of the above is outside my maths comfort zone, so if you spot an error shout it out.
Related articles
- NP-completeness and NP problems (cs.stackexchange.com)
- Some Updates (gilkalai.wordpress.com)
- Name My Book (computationalcomplexity.org)
- TBI Recovery – Please speak my language (brokenbrilliant.wordpress.com)
- Four theories on the cryptography of Star Trek (cryptographyengineering.com)

10 responses to “Even if P=NP we might see no benefit”
A few comments about whether linear programming (LP) is NP-hard:
1. The simplex method is known not to be polynomial in the worst case. The Klee-Minty cube (basically a multidimensional shaved die) has been used to prove it. (https://en.wikipedia.org/wiki/Klee%E2%80%93Minty_cube)
2. The simplex method being nonpolynomial does not, however, make LP NP-hard. That would require that no known algorithm be polynomial. Both Khachiyan’s ellipsoid algorithm (which turned out not to be as practical as first hoped) and interior point methods (commonly used today for some problems) are theoretically polynomial time. I believe they may not apply to every possible LP (IP methods, for instance, require the feasible region to have an interior), but I think one can at worst define a subset of LP problems, containing pretty much all the ones encountered in practice, where a polynomial-time algorithm exists. (https://en.wikipedia.org/wiki/Linear_programming#Interior_point)
3. That said, it turns out in practice that good old simplex is as fast as or faster than interior point methods on a sizeable percentage of actual problems.
4. About the time Khachiyan’s algorithm was getting a ton of press (I think), George Dantzig, the father of the simplex algorithm, made a comment along the lines of “a polynomial can be big too” (wording quite approximate; my memory fades). The point is that a polynomial algorithm will beat an exponential algorithm when the problem gets sufficiently huge. It’s an asymptotic result. While theoreticians care greatly whether a polynomial time algorithm exists, practitioners care greatly whether their particular problem instance (whatever size it happens to be) gets solved sooner rather than later.
Thanks for this. Am I right in thinking that what you have written doesn’t show my blog to be wrong but merely, um, lacking in detail? Or is there something I should change above? I guess the point I was trying to make is the one in your paragraph 4 – namely that people are likely to prefer working heuristics or approximations to slow polynomial solutions.
I agree with your last point. As to whether anything needs changing, it’s hard for me to say, since I can’t access the New Scientist article (no account there). Most of what you wrote looks fine, but I think the Hirsch conjecture might be a bit of a red herring in regard to P or NP. That may well be the fault of the NS article. The number of facets of a d-dimensional polytope with m vertices can be as much as m^floor(d/2) (see, for instance, Theorem 16 of http://www.postech.ac.kr/class/eece508/convex-polytopes.pdf), so even if Hirsch were true, the simplex method could (and, given Klee-Minty, would) still end up nonpolynomial.
In any event, whether or not P = NP, there will always be problems that take too long for our best algorithms to solve. How many “real-life” (v. academic) problems are among them will be interesting to watch. The traveling salesman problem is NP-complete, and when I started out a 20 node problem was out of reach for most of us. Quoting the Princeton University Press blog (http://press.princeton.edu/blog/2012/02/07/bill-cook-launches-companion-app-to-book-in-pursuit-of-the-traveling-salesman/): “Twenty-four years ago a 2,392-city example of the TSP was solved in a 23-hour run on a super computer to set a new world record. This same problem now solves in 7 minutes on an iPhone 4 thanks to a free app: Concorde TSP Solver!”
As algorithms get better (and computers get faster), we grasp for larger problems.
To be fair to them, they didn’t mention NP at all. They did comment on ‘strongly polynomial’ algorithms.
A paper has been published about P versus NP in IEEE-AL. Follow the arguments in my blog with some comments for dummies and the corresponding links of the published paper and the preprint(in spanish and english):
http://the-point-of-view-of-frank.blogspot.com/
Frank, thanks for the comment. Perhaps you could explain if the paper you have linked to is yours – there seems to be some confusion on that point as it is under a different name but the server reports it uses uncredited material from a paper you submitted and then withdrew.
Frank has replied to this to clear up the confusion see https://cartesianproduct.wordpress.com/2013/05/22/more-on-p-and-np/
“polyhedron” is three-dimensional. “Polytope” is the generalization to n dimensions. Hirsch’s conjecture is true for all polyhedra but not all polytopes.
I think that it is worth knowing that the simplex method deals with a feasible space that is the intersection of a bunch of half-spaces. So the feasible space will be a polytope and it will always be convex. That makes the problem a lot simpler to visualize, at least for me. (When I learned this, we called them convex hulls.)
Actually, “polyhedron” can refer to any number of dimensions; the difference between “polyhedron” and “polytope” is that the latter must be bounded. So polytopes are a subset of polyhedra. (See, for instance, http://glossary.computing.society.informs.org/index.php?page=P.html.)
prubin73: gosh, this must be an example where the terminology has multiple bindings.
The Penguin Dictionary of Mathematics agrees with me, and not with the g.c.s.i.o definition in a couple of ways: (1) polyhedra are 3d, and (2) need not be convex.
So does wikipedia. It does not mention convexity (why should it?) but their pictures include non convex ones.
Ahh. Mathworld gives a hint. It says that the geometry and algebraic topology use the word differently. http://mathworld.wolfram.com/Polyhedron.html You are using the algebraic topology definition. Shame on those algebraic topologists who broke a perfectly fine term, one dating back to the greeks!
Double ahh. My daughter the mathematician says that these definitions are fluid and in optimizing contexts, polyhedron convexity is assumed and so too multidimensionality.
Hmm. According to the bible (Rockafellar’s “Convex Analysis”), the intersection of a finite number of half-spaces is a “polyhedral convex set”, regardless of (finite) dimension. Extend to the noun form “polyhedron” and/or the nonconvex variant (which does come up in some contexts) at your own peril, I suppose. Rockafellar defines a “polytope” as the convex hull of a finite number of points (which guarantees it to be bounded).
The Wikipedia, as befits a document written by a group, tries to straddle all sides of the fence. Quoting https://en.wikipedia.org/wiki/Polyhedron#General_polyhedra: “More recently mathematics has defined a polyhedron as a set in real affine (or Euclidean) space of any dimensional n that has flat sides. It may alternatively be defined as the union of a finite number of convex polyhedra, where a convex polyhedron is any set that is the intersection of a finite number of half-spaces. It may be bounded or unbounded. In this meaning, a polytope is a bounded polyhedron.”
I’m not sure if this is topologists v. geometers or Brits v. right-thinking people. After all, not content with using a bunch of extraneous letters in various words, the Brits apparently gave us “convex downward” and “convex upward” for “convex” and “concave” respectively. The restriction of “polyhedron” to 2-d necessitates a countably infinite collection of words for higher dimensions (such as “polychoron” for four dimensions), just the sort of thing to appeal to people who like to invent more terms.
Speaking of which, any idea what the name for a five-dimensional set that has finitely many flat side? Polywhatchamacallit?